
こんにちは、コケコです。
今更ですが、ずっとずっと興味がありながらも「難しくて導入からわけわからん!」と
手を出せていなかった、stable diffusionを導入してみたので進捗レポです。
stable diffusionをPCに導入
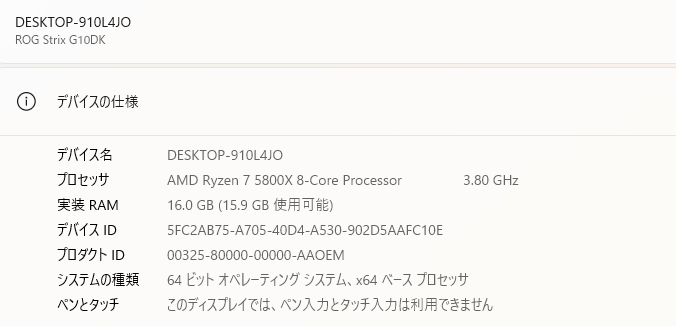
私のPCスペックは?
長らくstable diffusionの読み方もわからず検索すらできなかったためまず初めにやったことは、
「stable diffusion」をPCに単語登録することでした💦
私はWEB上で稼働ではなく自分のPC内にstable diffusionをダウンロードして起動→生成の方法を取りました。
今使用しているPCを購入するときに、私はPC音痴のためスペック等のことは全くわからないのですが、
できる気はしないけどいつか動画編集とか生成AIやってみたい…!
という願望だけはあったので、デスクトップタイプでグラボ?のスペックがそこそこあるものを
夫に見繕ってもらっていました。
ちなみに購入したPCはこれです。動画編集も生成もすごくスムーズにできて、
私にはオーバースペックなほど大満足です。
https://www.amazon.co.jp/dp/B0BCPXTMYG?ref=ppx_yo2ov_dt_b_fed_asin_title
そのためstable diffusionに必要なスペックもろくに調べませんでしたが、「まあ大丈夫でしょ!」という感じで
導入したら、今の所は何も問題なくスムーズに画像が生成できています。
参考になるかわかりませんが、私のPCのスペックを載せておきます。
いざPCにダウンロード
私には高レベルすぎて何のことやらわからない「パイソン」や「ギフ」などのダウンロードをこなし、
なんとか導入完了。
導入方法については
https://soroban.highreso.jp/article/article-036
こちらのサイトの通りに行いましたので、ここでは割愛します。
わかりやすい記事をありがとうございました。
 コケコ
コケコちなみに、stable diffusion自体や、のちに出てくる「モデル」等は
容量が重く非常にメモリを食います。
(導入2日目で既に11GBくらい…)
そのためPCにまだ余裕メモリはありましたが、
私は導入後に持っていた外付けSSDにstable diffusionフォルダを
移しました。
PC本体から起動するより少し時間がかかりますが、
問題なく起動自体はできます。
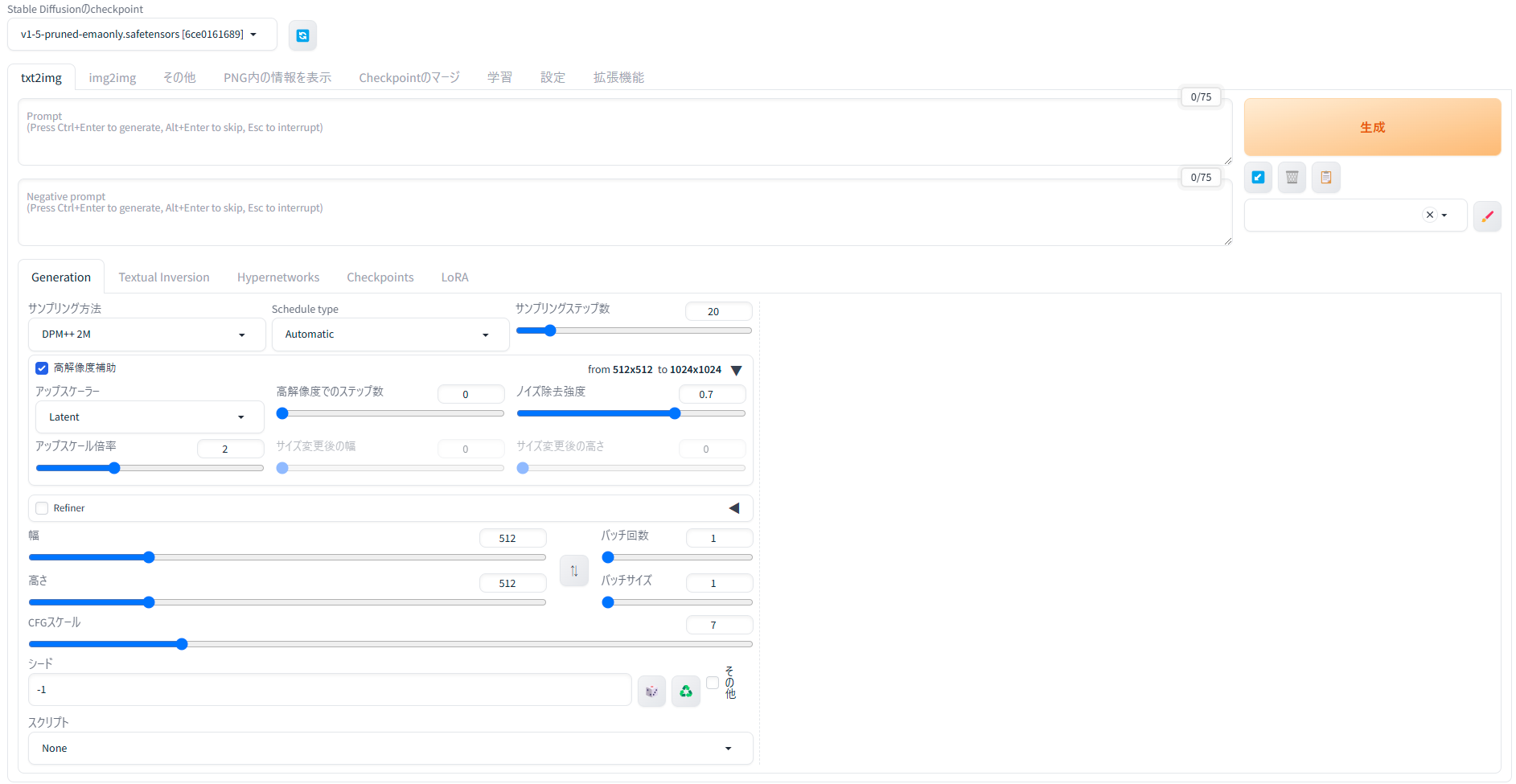
日本語版にする
上記サイト通りに、ローカルにとりあえず導入したのはいいものの、言語デフォルトが英語なので
何をどうしてよいのかさっぱりわからないので、次にstable diffusionを日本語版にしました。
参考サイトはhttps://romptn.com/article/6275 こちら。
わかりやすい記事を本当にありがとうございました。
なんとか日本語版になった画面がこちら。
初のプロンプト入力
画像を生成するにはプロンプトなる英単語を指示入力する、ということだけは知っていたので、
とりあえず「プロンプト」と書かれた欄には
dinosaur,near future (恐竜・近未来)
と謎の文言を入力してみました。
ちなみに、これらは全て英語で書かないといけないのですが私は英単語が冗談ではなく全くわからないので、
グーグル翻訳に頼って変換しようとしたのですが、夫から
 寝坊主
寝坊主そんなことしなくても、ChatGPTに単語と指示を書いた方が
早いんじゃない?
コケコ?????
という有難い助言を頂いたのでそのようにしてみました。
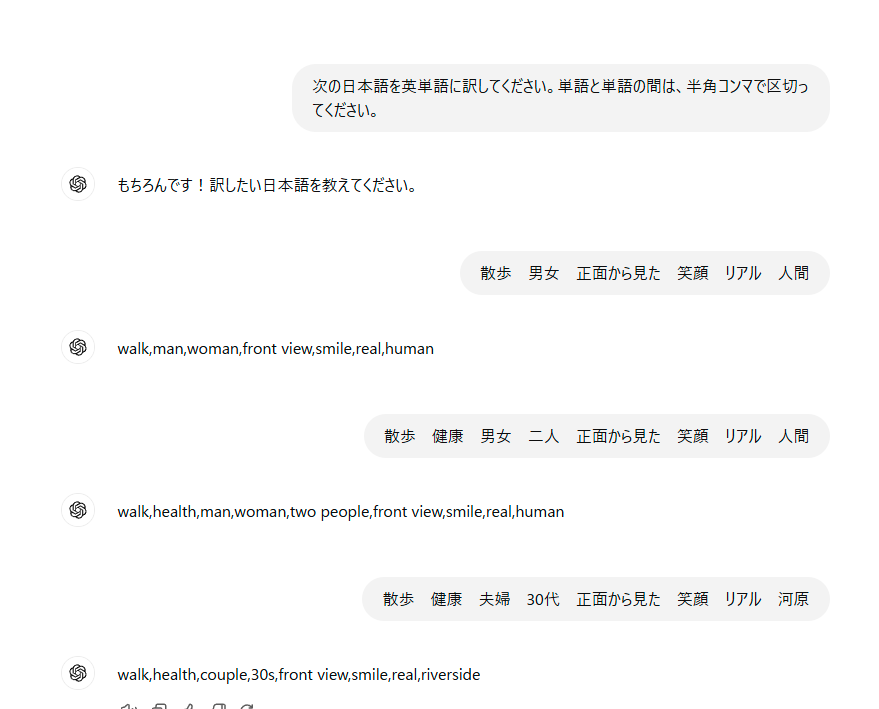
こんな感じで続けていけば、衝撃的なことに英単語を一つも覚えていない私でも
あっという間に英語プロンプトができてしまいます。
ありがとうAI、そしてそれを的確に使える夫。
AIを使うってこういうことなんだなあとしみじみ感動しました。
さて、先ほどのプロンプトで、何の設定もいじらずに生成できた画像がこちらです。

確かに恐竜です!腐った緑色の部分も、羽毛に見えなくもない!
ただアングルも大きさも何も指定していないので全く全体像がわからないし、
目なのか鼻なのかわからない謎パーツもあります。
生成AIソフトが出始めてから2年くらい経っているので、
誰でも超適当にやってもよくX等で見る美麗な画像が生成されるのかと思っていたのですが、
さすがにそうではないということを初めて知りました。
その後四つ葉のクローバーを抱きしめた女の子の画像を作りたいと思い入れてみたプロンプト。
quatrefoil,clover,held you,girl
画像がこちら。

数年前生成AIが出始めて、人の顔や手指が明らかにおかしいといわれていた時代を思い出します。
やっぱり技術がないと見れる画像には全然ならないのですね…。
サンプリング回数
数回作ってみて、「サンプリング回数」というものを増やすと画像ができるまでの時間は長くなるけど指示に近い画像ができていくということを知りました。

廃墟、蔦、大きな窓 などのプロンプトとサンプリング回数20で作成。
これをサンプリング回数のみ20→100に変更した結果

こんな風に変わりました。
小道具は増えてちょっと廃墟の建物感が増した気がします。
また、ブログのアイキャッチ用に「夫婦が散歩している画像」を作ってみたくて色々といじってみました。
walk,man,woman,front view,smile,real,human(散歩 男女 正面から見た 笑顔 リアル 人間)
↓

男女では人数をはっきり認識してくれないみたいです。顔の生成は非常に気持ちが悪いです。
walk,health,man,woman,two people,front view,smile,real,human
(散歩 健康 男女 二人 正面から見た 笑顔 リアル 人間)
↓

人数はしっかりと絞られて夫婦っぽくなりましたが、相変わらず顔と指の生成がひどいです。
それと服もワンパターンですね。
walk,health,couple,30s,front view,smile,real,riverside,Japanese
(散歩 健康 夫婦 30代 正面から見た 笑顔 リアル 河原 日本人)
↓


なんで顔がこんなに気持ち悪い!?あと正面からって言ってるのに…。
結局実用的な画像が全然作れず、仕方がないので生成はあきらめました。
技術が進歩しているしネット上では何の違和感もない美麗なAI画像ばかり見ることができるので
私でもすぐに作れると思っていましたが、本当に難しいです。
本日はここまでです。
頑張って理想のAI画像を作るぞー!!
・ネガティブプロンプトを入れる
・モデルを入れてみる

コメント